NVIDIA DGX SuperPOD AI400X2
View as PDF
NVIDIA DGX SuperPOD: DDN AI400X2 Appliance
The NVIDIA DGX SuperPOD™ with NVIDIA DGX™A100 systems is an artificial intelligence (AI) supercomputing infrastructure, providing the computational power necessary to train today’s state-of-the-art deep learning (DL) models and to fuel future innovation. The DGX SuperPOD delivers ground-breaking performance, deploys in weeks as a fully integrated system, and is designed to solve the world’s most challenging computational problems.
This DGX SuperPOD reference architecture (RA) is the result of collaboration between DL scientists, application performance engineers, and system architects to build a system capable of supporting the widest range of DL workloads. The ground-breaking performance delivered by the DGX SuperPOD with DGX A100 systems enables the rapid training of DL models at great scale. The integrated approach of provisioning, management, compute, networking, and fast storage enables a diverse, multi-tenant system that can span data analytics, model development, and AI inference.
In this paper, the DDN® AI400X2 appliance was evaluated for suitability for supporting DL workloads when connected to the DGX SuperPOD. AI400X2 appliances are compact and low-power storage platforms that provide incredible raw performance with the use of NVMe drives for storage, and InfiniBand or Ethernet (including RoCE) as its network transport. Each appliance fully integrates the DDN EXAScaler parallel filesystem, which is optimized for AI and HPC applications. EXAScaler is based on the open-source Lustre filesystem with the addition of extensive performance, manageability, and reliability enhancements. Multiple appliances can be aggregated into a single filesystem to create very large namespaces. A turnkey solution validated at scale with the DGX SuperPOD, the AI400X2 appliance is backed by DDN global deployment and support services.
Shared parallel filesystems such as the EXAScaler filesystem simplify data access and support additional use cases where fast data is required for efficient training and local caching is not adequate. With high single-threaded and multi-threaded read performance, they can be used for:
- Training when the datasets cannot be cached locally in DGX A100 system memory or on the DGX A100 NVMe RAID.
- Fast staging of data to local disk.
- Training with large individual data objects (for example, uncompressed or large lossless compressed images).
- Training with optimized data formats such as TFRecord and RecordIO.
- Workspace for long term storage (LTS) of datasets.
- A centralized repository for the acquisition, manipulation and sharing of results via standard protocols like NFS, SMB, and S3.
Storage Overview
Training performance can be limited by the rate at which data can be read and reread from storage. The key to performance is the ability to read data multiple times, ideally from local storage. The closer the data is cached to the GPU, the faster it can be read. Storage needs to be designed considering the hierarchy of different storage technologies, either persistent or nonpersistent, to balance the needs of performance, capacity, and cost.
The storage caching hierarchy of the DGX A100 system is shown in Table 1. Depending on data size and performance needs, each tier of the hierarchy can be leveraged to maximize application performance.
Table 1. DGX A100 system storage and caching hierarchy

Caching data in local RAM provides the best performance for reads. This caching is transparent once the data is read from the filesystem. However, the size of RAM is limited to 2.0 TB on a DGX A100 > 50 GB/s per system system and that capacity must be shared with the operating system, application, and other system processes. The local storage on the DGX A100 system provides 30 TB of PCIe Gen 4 NVMe SSD storage. While the local storage is fast, it is not practical to manage a dynamic environment with local disk alone in multi-node environment. Functionally, centralized storage can be as quick as local storage on many workloads.
Performance requirements for high-speed storage greatly depend on the types of AI models and data formats being used. The DGX SuperPOD has been designed as a capability-class system that can handle any workload both today and in the future. However, if systems are going to focus on a specific workload, such as natural language processing, it may be possible to better estimate performance needs of the storage system.
To allow customers to characterize their performance requirements, some general guidance on common workloads and datasets are shown Table 2.
Table 2. Characterizing different I/O workloads

Table 3 provides performance estimates for the storage system necessary to meet the guidelines in Table 2. To achieve these performance characteristics may require the use of optimized file formats, TFRecord, RecordIO, or HDF5.
Table 3. Guidelines for desired storage performance characteristics

The high-speed storage provides a shared view of an organization’s data to all systems. It needs to be optimized for small, random I/O patterns, and provide high peak system performance and high 5 aggregate filesystem performance to meet the variety of workloads an organization may encounter.
About the DDN AI400X2 Appliance
The DDN AI400X2 appliance, meets the requirements above and provides several features that are important for maximizing the performance of the DGX SuperPOD and system management in data centers.
Some of features of the DDN AI400X2 appliance include:
- The AI400X2 appliance is a scalable building block that can be easily clustered into a single namespace that scales seamlessly in capacity, performance, and capability. It is fully integrated which streamlines deployment and simplifies management operations.
- An AI400X2 appliance can be configured at several different capacities ranging from 30 TB to 500 TB for NVME and can be expanded with up to 5 PB of capacity disk for hybrid configuration. Multiple appliances can be aggregated into a single namespace that provides up to several hundreds of petabytes of useable capacity.
- The AI400X2 appliance communicates with DGX SuperPOD clients using multiple HDR200 InfiniBand or 200 GbE network connections for performance, load balancing, and resiliency.
- Native InfiniBand support is a key feature that maximizes performance and minimizes CPU overhead. Since the DGX SuperPOD compute fabric is InfiniBand, designing the storage fabric as InfiniBand means only one high-speed fabric type needs to be managed, simplifying operations.
- The DDN shared parallel protocol enables a single DGX client to access the full capabilities of a single appliance—over 90 GB/s and 3M IOPS. Multiple clients can access data on the appliance simultaneously, with performance available to all systems and distributed dynamically. Clients can be optimized for ultra-low latency workloads.
- The all-NVME architecture of the AI400X2 appliance provides excellent random read performance, often as fast as sequential read patterns.
- The DDN AI400X2 appliance is space and power efficient with dense performance and capacity, achieving optimal data center utilization and better operational economics.
Validation Methodology and Results
Three classes of validation tests are used to evaluate a particular storage technology and configuration for use with the DGX SuperPOD: microbenchmark performance, real application performance, and functional testing. The microbenchmarks measure key I/O patterns for DL training and are crafted so they can be run on nodes with CPU only. This reduces the need for large GPU-based systems only to validate storage. Real DL training applications are then run on a DGX SuperPOD to confirm that the applications meet expected performance. Beyond performance, storage solutions are tested for robustness and resiliency as part of a functional test.
NVIDIA DGX SuperPOD storage validation process leverages a “Pass or Fail” methodology. Specific targets are set for the microbenchmark test. Each benchmark result is graded as good, fair, or poor. A passing grade is one where at least 80% of the tests are good, and none are poor. In addition, there must be no catastrophic issues created during testing. For application testing, a passing grade is one where all cases complete within 5% of the roofline performance set by running the same tests with data staged on the DGX A100 RAID. For functional testing, a passing grade is one where all functional tests meet their expected outcomes.
Microbenchmarks
Table 3 lists several high-level performance metrics that storage systems must meet to qualify as a DGX SuperPOD solution. Current testing requires that the solution meet the “Best” criteria discussed in the table. In addition to these high-level metrics, several groups of tests are run to validate the overall capabilities of the proposed solutions. These include single-node tests where the number of threads is varied and multi-node tests where a single thread count is used and as the number of nodes vary. In addition, each test run in both Buffered and DirectIO modes and when I/O is performed to separate files or when all threads and nodes operate on the same file.
Four different read patterns are run. The first read operation is sequential where no data is in the cache. The second read operation is executed immediately after the first to test the ability for the filesystem to cache data. The cache is purged and then the data are read again, this time randomly. Lastly, the data is reread again randomly, to test data caching.
IOR benchmark for single-node and multi-node tests was used.
Hero Benchmark Performance
The hero benchmark helps establish the peak performance capability of the entire solution. Storage parameters, such as filesystem settings, I/O size, and controlling CPU affinity, were tuned to achieve the best read and write performance. Storage devices were expected to demonstrate that the quoted performance was close to the measured performance. For the other tests, not every I/O (or any) pattern to be able to achieve this level of performance, but it provides and understanding of the difference between peak and obtainable performance of the I/O patterns of interest.
The delivered solution for a single SU had to demonstrate over 20 GiB/s for writes and 65 GiB/s for reads. Ideally, the write performance should be at least 50% of the read performance. However, some storage architectures have a different balance between read and write performance, so this is only a guideline and read performance is more important than write.
Single-Node, Multi-File Performance
For single-node performance, I/O read and write performance is measured by varying the number of threads in incremental steps. Each thread writes (and reads) to (and from) its own file in the same directory.
For single-node performance tests, the number of threads is varied from 1 to the ideal number of threads to maximize performance (typically more than half the cores 64, but no more than the total physical cores, 128). The I/O size is varied between 128 KiB and 1 MiB and the tests are run with Buffered I/O and Direct I/O.
The target performance for these tests is shown in Table 4.
Table 4. Single-node, multi-file performance targets
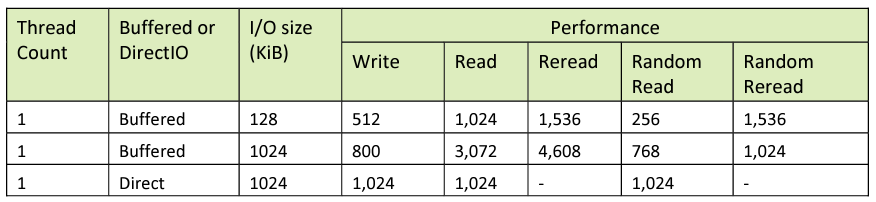
When maximizing single-node performance, the thread count may vary, however it is expected that performance does not drop significantly when additional threads are used beyond the optimal thread count.
Target performance for single-node performance with multiple threads is in Table 5. The optimal number of threads may vary for any particular storage configuration.
Table 5. Single-node, multi-threaded performance targets
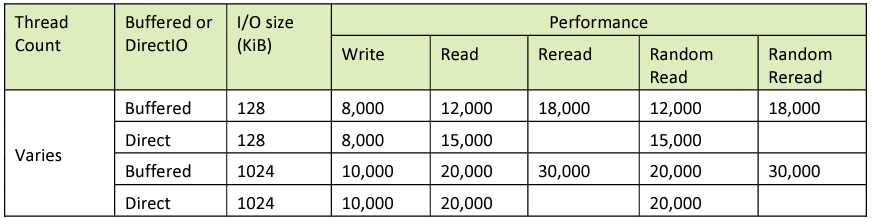
Reread performance relative to read performance can vary substantially between different storage solutions. The reread performance should be at least 50% of the read performance for both sequential and random reads.
Multi-Node, Multi-File Performance
The next test performed is multi-node I/O read and write test to make sure that the storage appliance can provide the minimum required buffered read and write per system for the DGX SuperPOD. The purpose of this benchmark is to test a given filesystems capability to scale performance of different I/O patterns. Performance should scale linearly from 1 to a few nodes, reach a maximum performance, then not drop off significantly as more nodes are added to the job.
The target performance for a single SU of 20 nodes is 65 GiB/s for reads with I/O size of 128 KiB or 1,024 KiB, and if the I/O is Direct or Buffered. The write performance should be at least 20 GiB/s, but ideally it would be 50% of the read performance. Results from these have to be interpreted carefully as it is possible to just add more hardware to achieve these levels. Overall performance is the goal, but it is desirable that the performance comes from an efficient architecture that is not over-designed for its use.
Single-File I/O Performance
A key I/O pattern is reading data from a single file. Often the fastest way to read data when all the data are organized into a single file, such as the RecordIO format. This can often be the fastest way to read data because it eliminates any of the open and close operations required when data are organized into multiple large files. Single-file reads are a key I/O pattern on DGX SuperPOD configurations.
Targeted performance and expected I/O behavior is that the single-node, multi-threaded, writes can successfully create the file, that sequential read and random read performance is good, and that read performance scales as more nodes are used. Multi-node, multi-threaded, single file writes are not tested. In addition, it is expected that buffered reread performance be similar to the multi-file reread performance.
Target performance for single file I/O is in Table 6.
Table 6. Single file read performance targets.

Application Testing
Microbenchmarks provide indications of the peak performance of key metrics. However, it is application performance that is most important. A subset of the MLPerf Training benchmarks are used to validate storage performance and function. Here, both single-node and multi-node configurations are tested to ensure that the filesystem can support different I/O patterns and workloads. Training performance when data are staged on the DGX A100 RAID was used as the baseline for performance. The performance goal is for the total to train when data are staged on the shared filesystem are within 5% of those measured when data are staged on the local raid. This is not just for individual runs, but also when multiple cases are run across the DGX SuperPOD at the same time.
ResNet-50
ResNet-50 is the canonical image classification benchmark. It is dataset size is over 100 GiB and has a requirement for fast data ingestion. On a DGX A100 system, a single node training requires approximately 3 GiB per second and the dataset is small enough that it can fit into cache. Preprocessing can vary, but the typical image size is approximately 128 KiB. One challenge of this benchmark is that at NVIDIA the processed images are stored in the RecordIO format, which is one large file for the entire dataset since this provides the best performance for MLPerf. Since it is a single file, this can stress share filesystem architectures that do not distribute the data across multiple targets or controllers.
Natural Language Processing–BERT
BERT is the reference standard natural language processing model. In this test, the system is filled with two eight node jobs and four single node jobs (or less if not all 20 nodes of the SU are available). It is expected that the total time to train is within 5% of that measured when training from the local raid. This test does not stress the filesystem but does test to ensure that local caching is operating as needed.
Recommender–DLRM
The recommender model has different training characteristics than ResNet-50 and BERT in that the model trains in less than a single epoch. This means that the data set is read no more than once, and local caching of data cannot be used. To achieve full training performance, DLRM must be able to read data at over 6 GiB/s. In addition, the file reader uses DirectIO that stresses the filesystem differently than the other two files. The data are formatted into a single file.
This test is only run as a single node test; however, several tests are run where the number of simultaneous jobs vary from one to the total number of nodes available. It is expected that the shared filesystem only sustains performance up to the peak performance measured from the hero test. For 20 simultaneously cases, the storage system would have to provide of over 120 GiB/s of sustained read performance, more than what is prescribed in Table 3. Even the best performance outlined in this table is not meant to support every possible workload. It is meant to provide a balance of high throughput while not over-architecting the system.
Functional Testing
In addition to performance, it is necessary to ensure that the storage solution is designed to meet the requirements of DGX SuperPOD integration and that it has been designed for the highest levels of uptime. To validate the solution’s resiliency, it is put through several tests to ensure that failure of one component will not interrupt the DGX SuperPOD operation. The tests are shown in Table 7.
Table 7. Functional tests

Summary
NVIDIA evaluations show that the DDN AI400X2 appliance meets the DGX SuperPOD performance and functionality requirements. It is a great choice to pair with a DGX SuperPOD to meet current and future storage needs.
As storage requirements grow, AI400X2 appliances can be added to seamlessly scale capacity, performance, and capability. The combination of NVME hardware and DDN’s shared parallel file system architecture provides excellent random read performance, often just as fast as sequential read patterns. With the 2U form factor, storage pools can be configured to meet or exceed the performance requirements of a DGX SuperPOD.
DGX SuperPOD customers should be assured that the AI400X2 appliance will meet their most demanding I/O needs.
Related Resources
